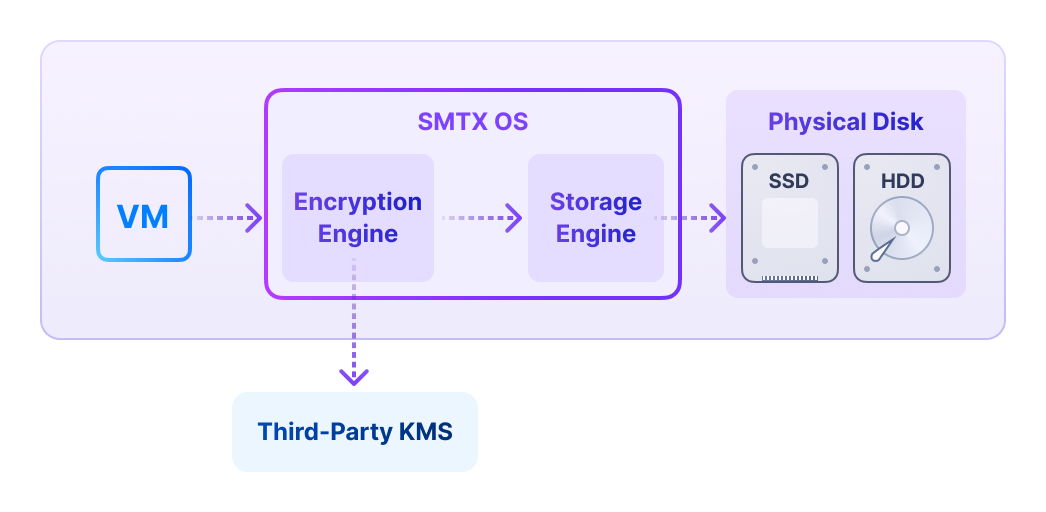
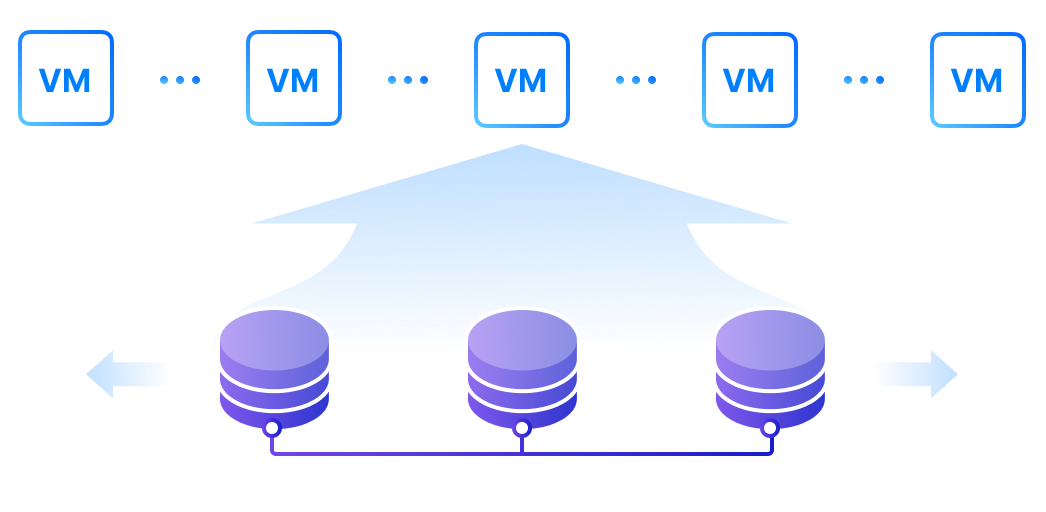
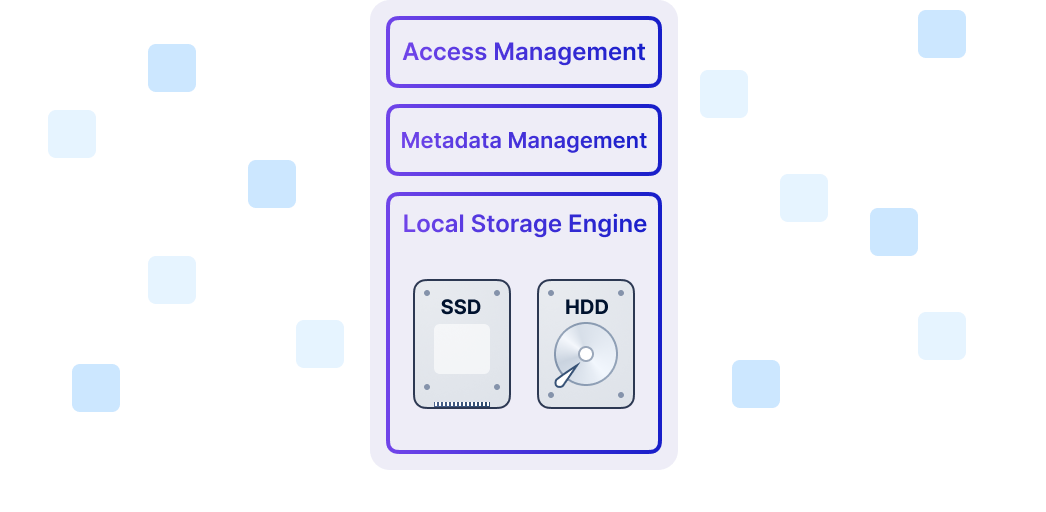
SMTX OS Product Component
Distributed Block Storage ZBS
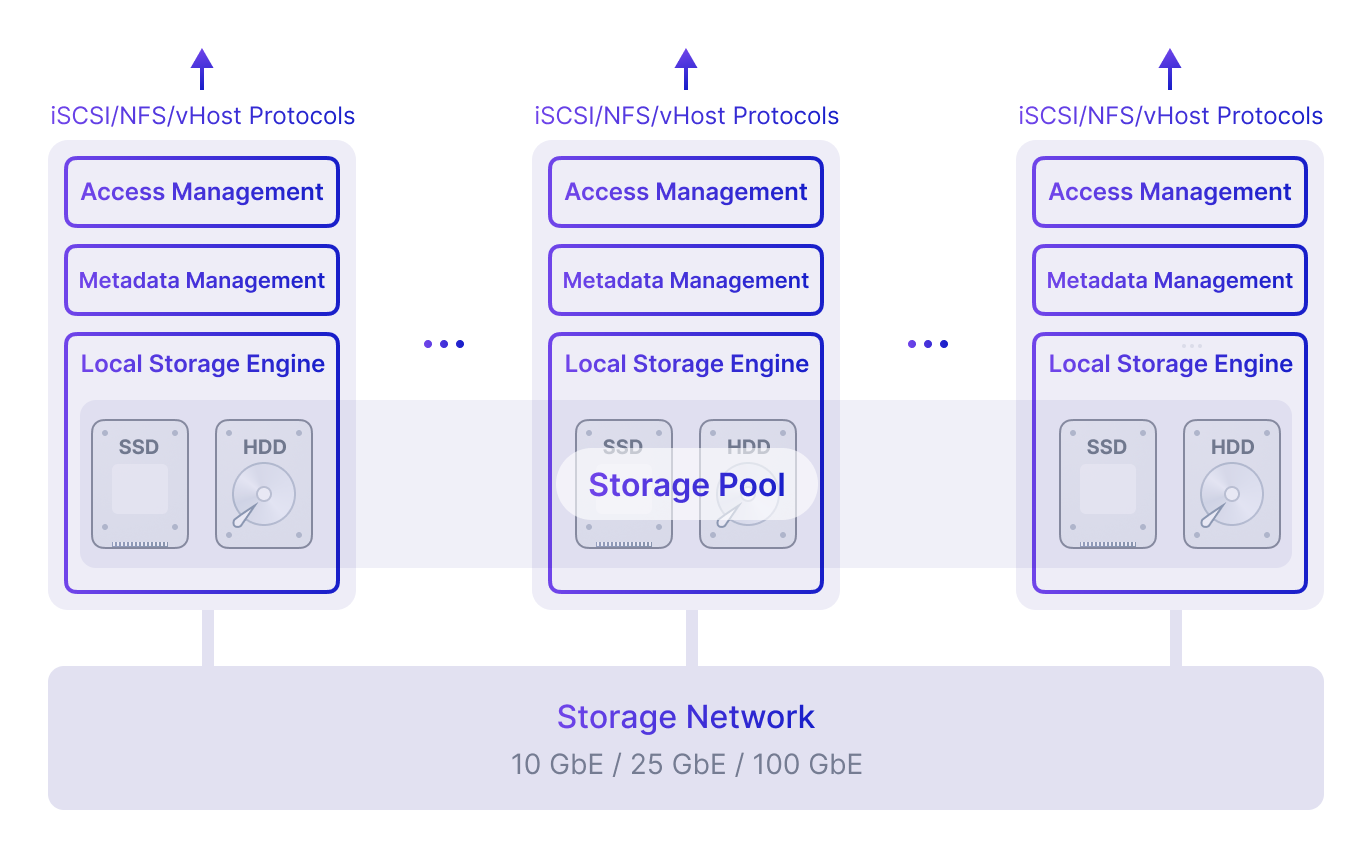
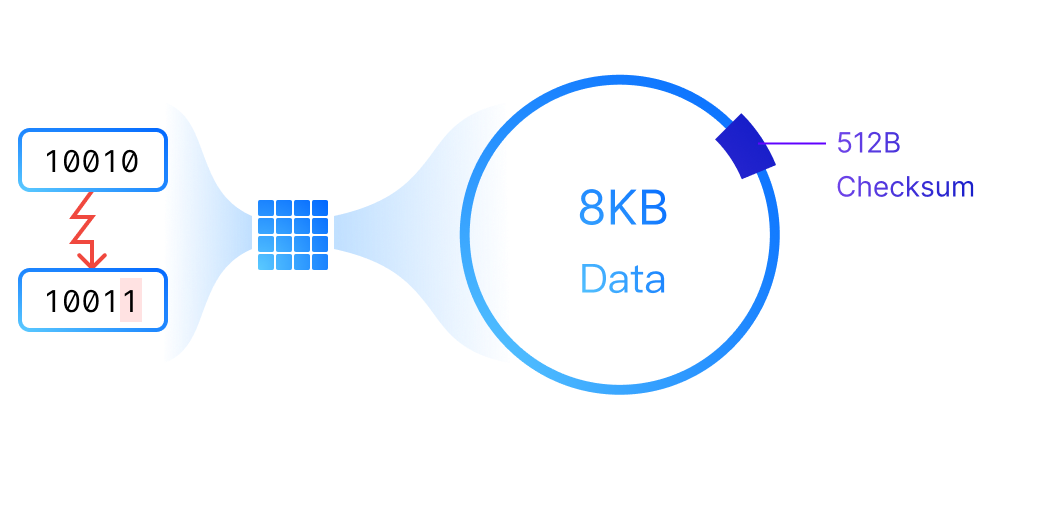
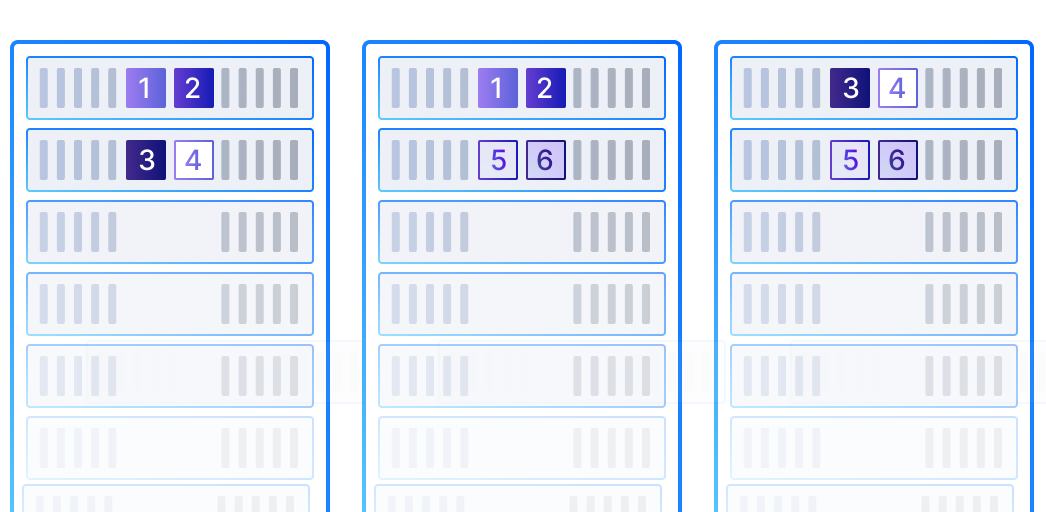
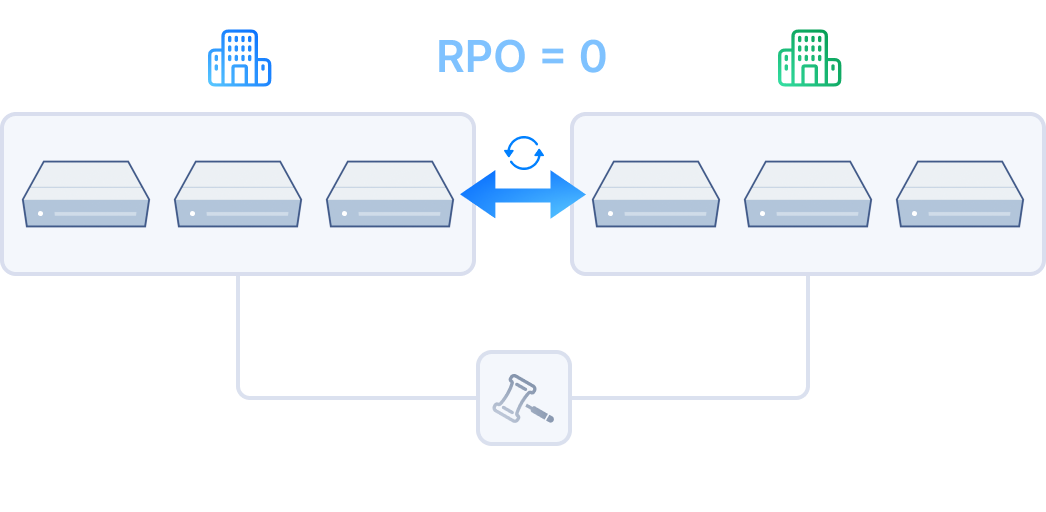
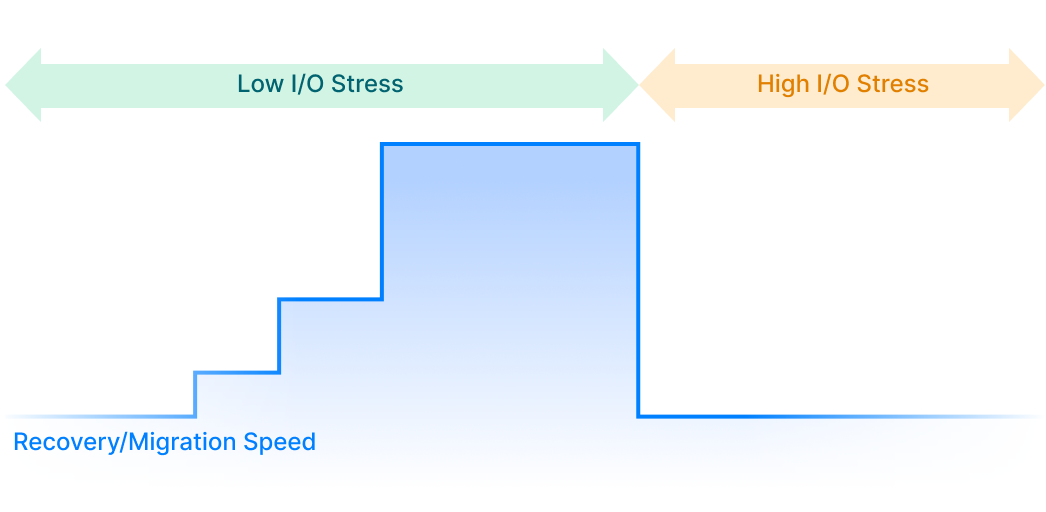
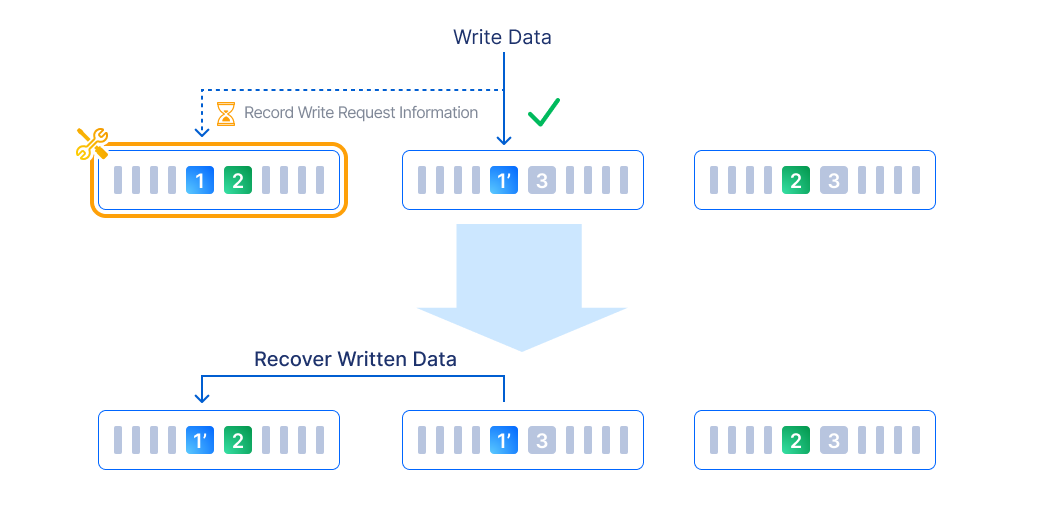
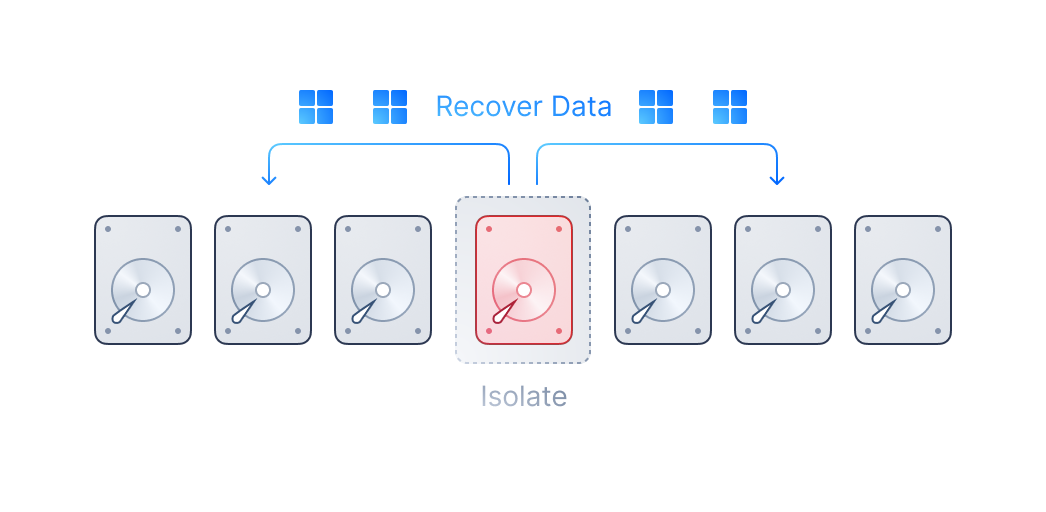
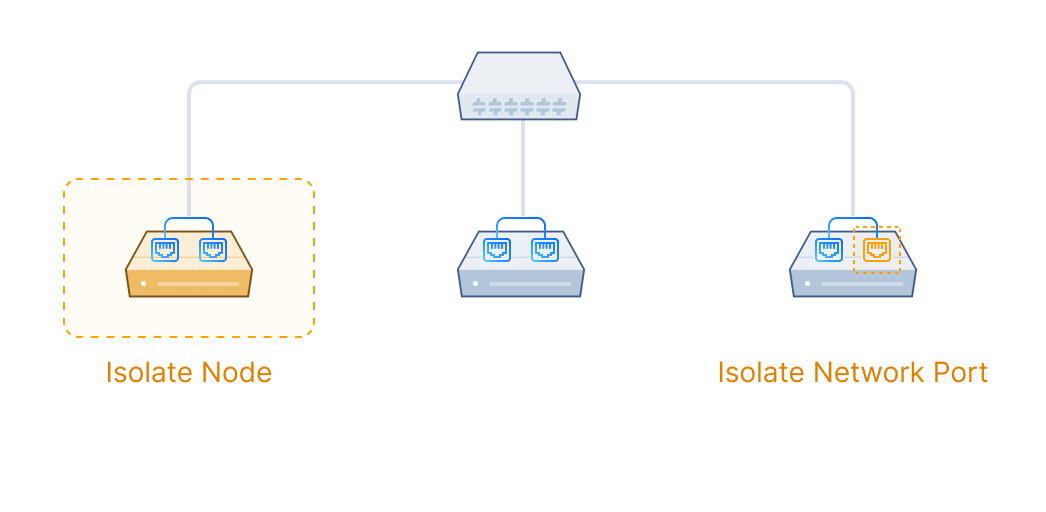
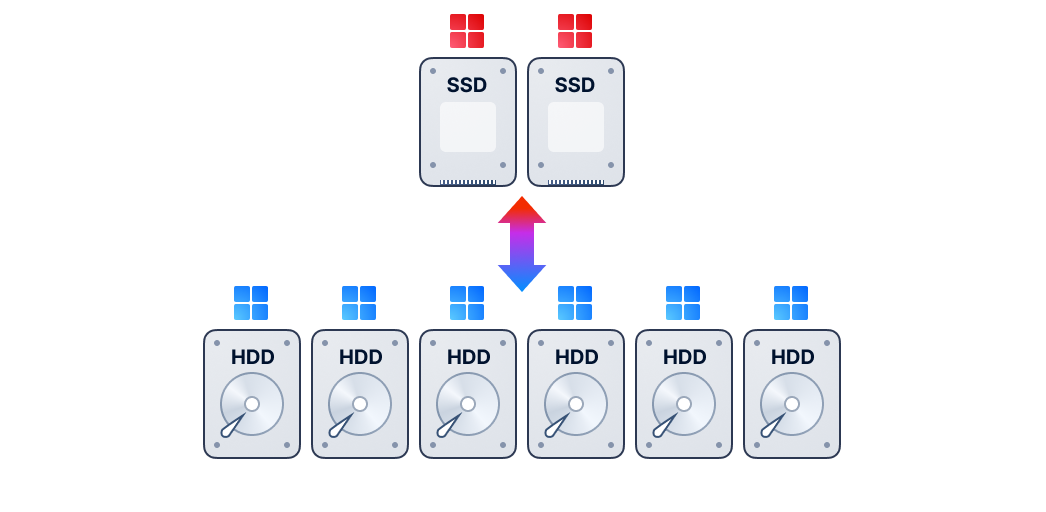
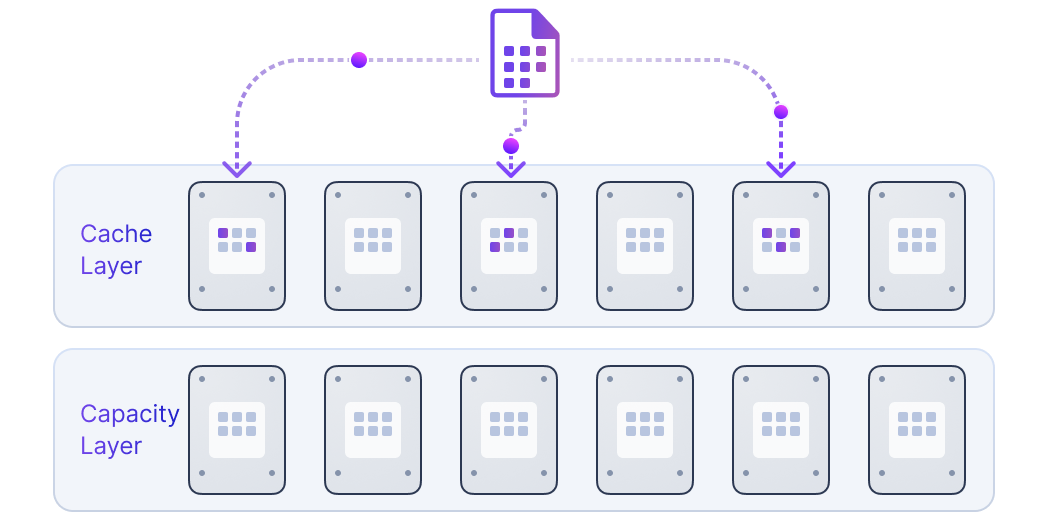
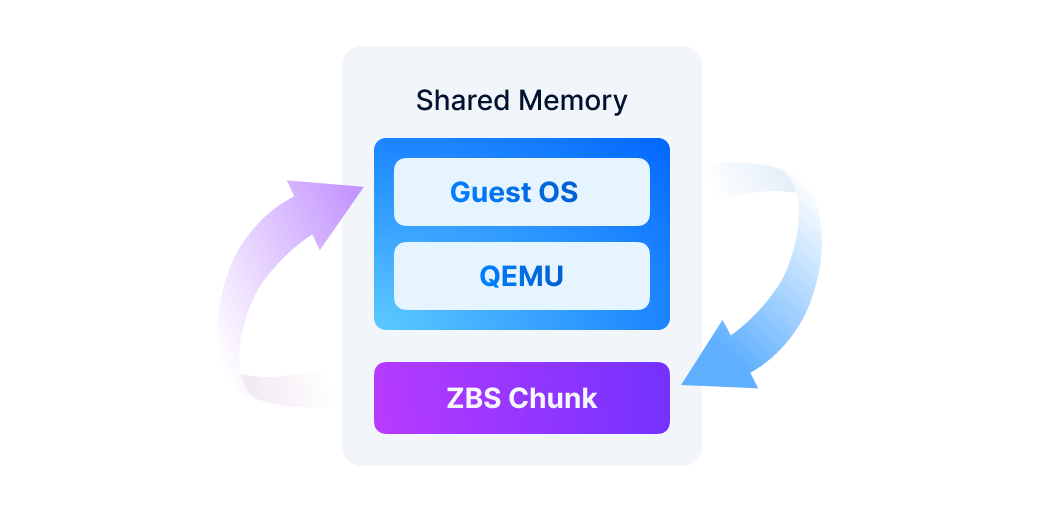
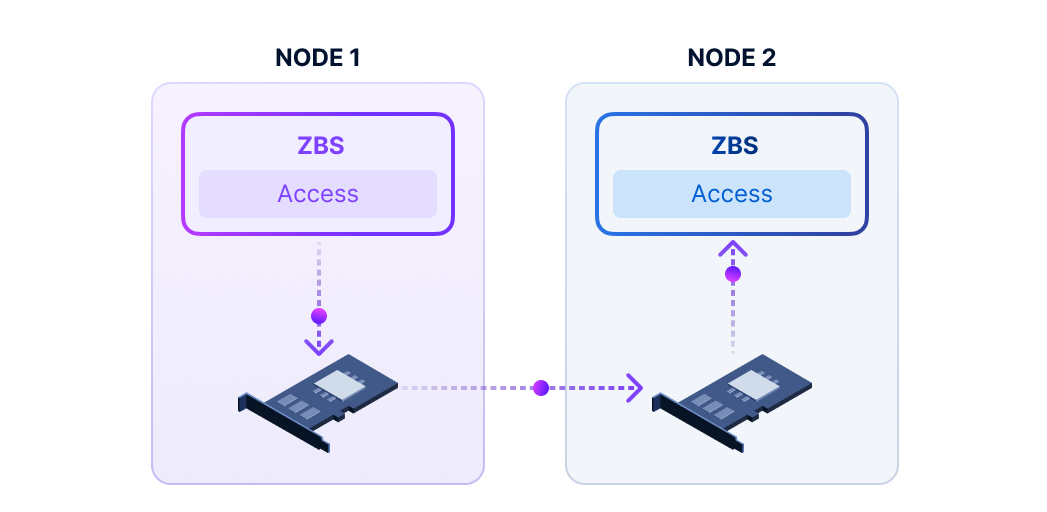
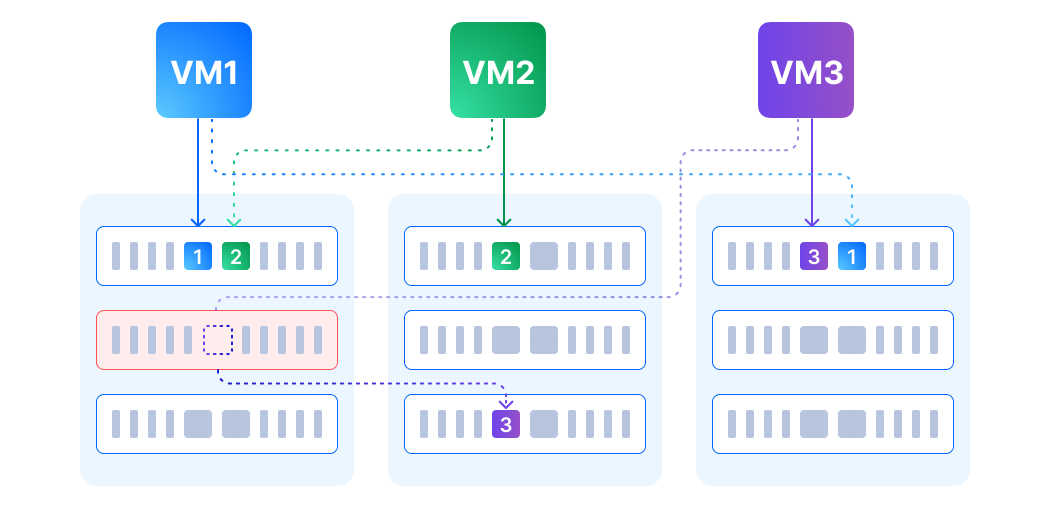
Distributed block storage with high performance, high availability, and production readiness.
ZBS is SmartX’s native storage product with performance and availability battle-tested in production. ZBS can be deployed with ELF in the form of SMTX OS.